
Recently we finished migrating the GitLab.com monolithic Postgres database to two independent databases: Main and CI. After we decided how to split things up, the project took about a year to complete.
This blog post on decomposing the GitLab backend database is part one in a three-part series. The posts give technical details about many of the challenges we had to
overcome, as well as links to issues, merge requests, epics, and developer-facing documentation.
Our hope is that you can get as much detail as you want about how we work on complex projects at GitLab.
We highlight the most interesting details, but anyone undertaking a similar
project might learn a lot from seeing all
the different trade-offs we evaluated along the way.
- "Decomposing the GitLab backend database, Part 1" focuses on the initial design and planning of the project.
- Part 2 focuses on the
execution of the final migration. - Part 3 highlights some interesting technical challenges we had to solve along the way, as well as some surprises.
How it began
Back in early 2021, GitLab formed a "database sharding" team in an effort to
deal with our ever-growing monolithic Postgres database. This database stored
almost all the data generated by GitLab.com users, excluding git data and some other
smaller things.
As this database grew over time, it became a common source of
incidents for GitLab. We knew that eventually we had to move away from a single
Postgres database. We were already approaching the limits of what we could do
on a single VM with 96 vCPU and continually trying to vertically scale this VM
would eventually not be possible. Even if we could vertically scale forever,
managing such a large Postgres database just becomes more and more difficult.
Even though our database architecture has been monolithic for a long time, we already made use of many scaling techniques, including:
- Using Patroni to have a pool of replicas for read-only traffic
- Using PGBouncer for pooling the vast number of connections across our application fleet
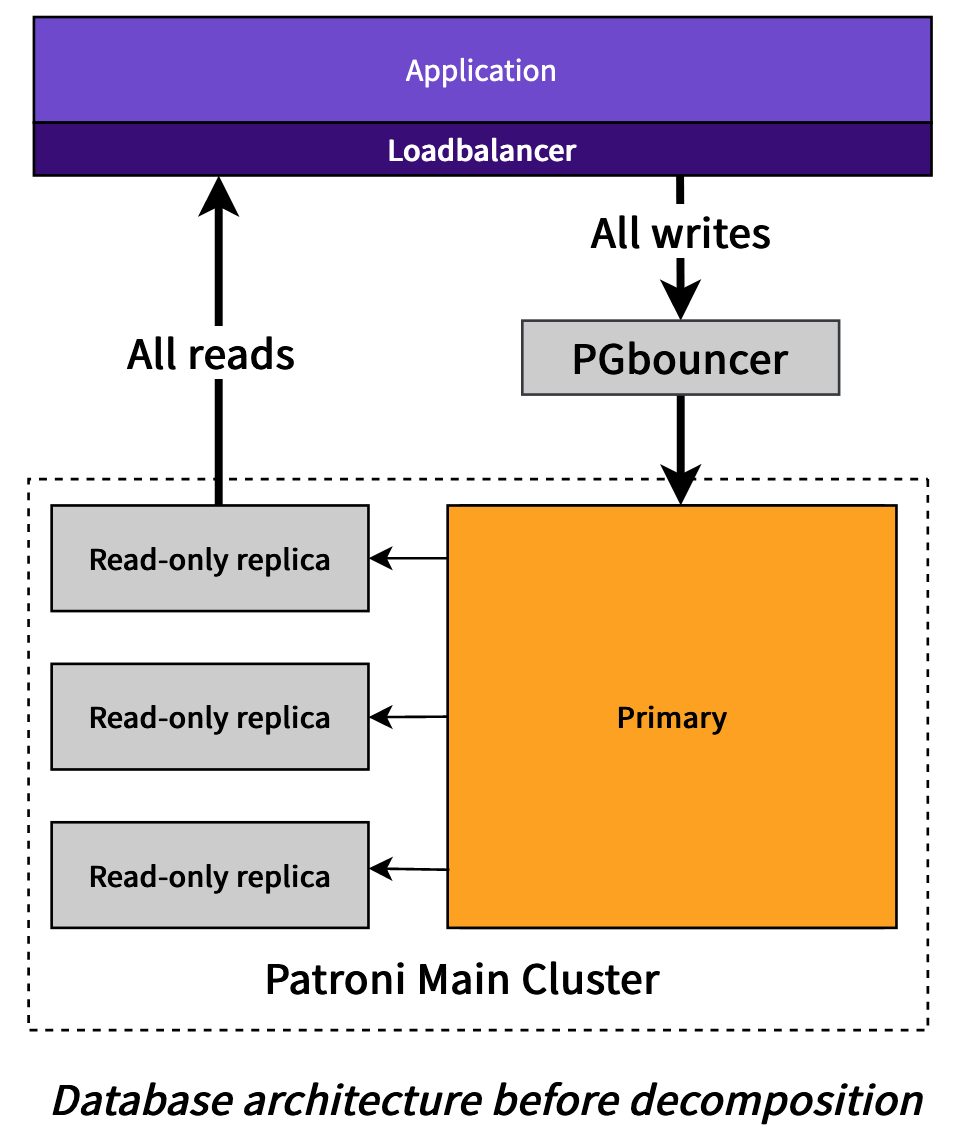
These approaches only got us so far and ultimately would never fix the scaling
bottleneck of the number of writes that need to happen, because all writes need to
go to the primary database.
The original objective of the database sharding team was to find a viable way
to horizontally shard the data in the database. We started with exploring
[sharding by top-level namespace][sharding_by_top_level_namespace_poc_epic]. This approach had some very complicated problems to solve, because the application
was never designed to have strict tenancy boundaries around top-level
namespaces. We believe that ultimately this will be a good way to split and
scale the database, but we needed a shorter term solution to our scaling
problems.
This is when we evaluated different ways to extract certain tables into a
separate database. This approach is often referred to as "vertical
partitioning" or "functional decomposition." We assumed this extraction would likely
be easier, as long as we found a set of tables with loose coupling to the rest
of the database. We knew it would require us to remove all joins to the rest of the
tables (more on that later).
Figuring out where most write activity occurs
We did [an analysis][analysis_of_decomposition_tables] of:
- Where the bulk of our data was stored
- The write traffic (since ultimately the number of writes was the thing we were trying to reduce)
We learned that CI tables (at the time) made up around 40% to 50% of our write traffic. This seemed like a
perfect candidate, because splitting the database in half (by write traffic) would be
the optimal scaling step.
We analyzed the data by splitting the database the following ways:
| Tables group | DB size (GB) | DB size (%) | Reads/s | Reads/s (%) | Writes/s | Writes/s (%) |
|---|


